GPT-5.5 Saturates Our Offensive Cybersecurity Time Horizons
Executive summary
In March 2026 we applied METR’s time-horizon methodology to offensive cybersecurity [1]. Our dataset covered seven benchmarks with professional human baselines. The best models reached a 50% time horizon of roughly three hours, on a 2024-onward trend doubling every six months. Those numbers were lower bounds. Our 2M-token evaluation budgets undercounted frontier capability.
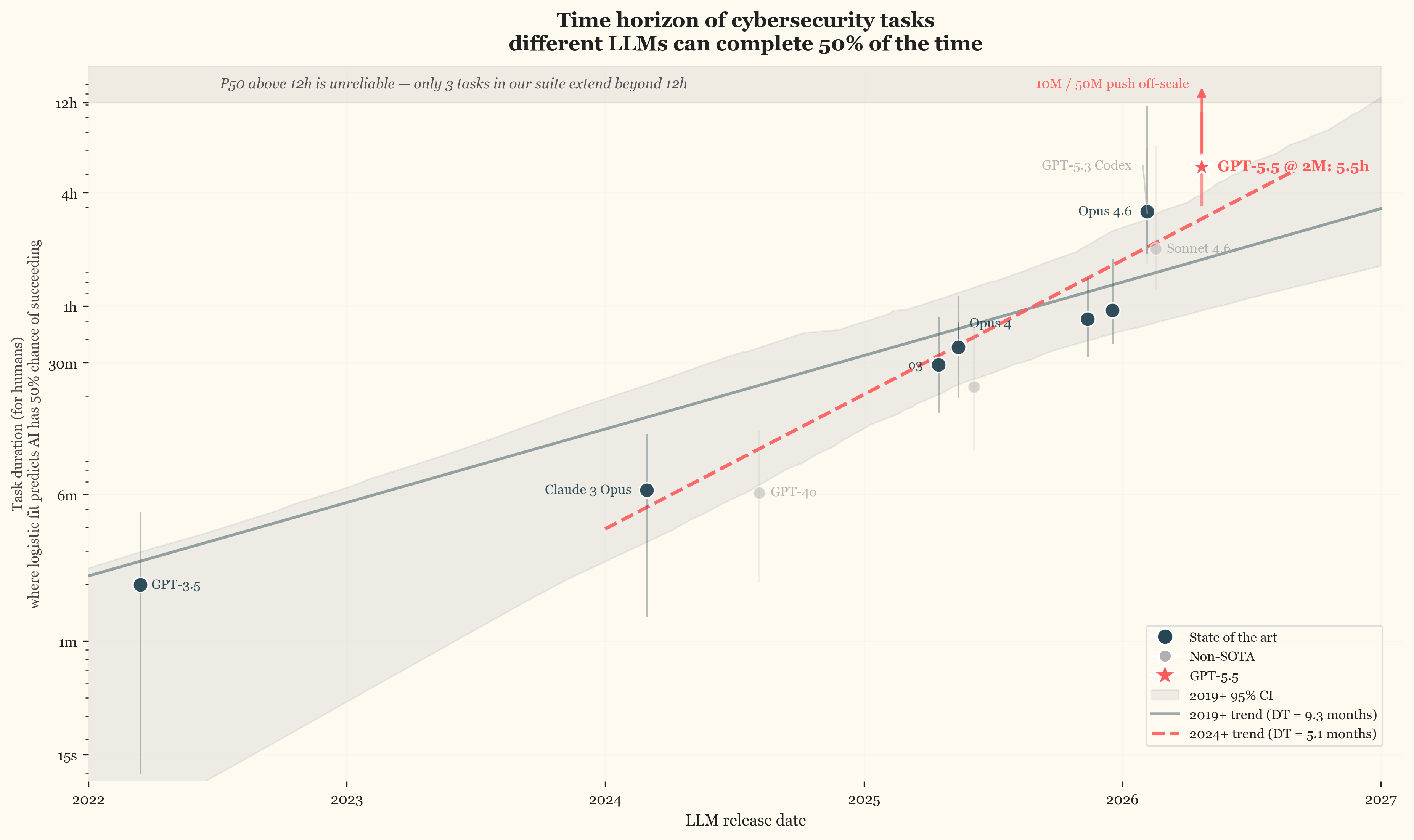
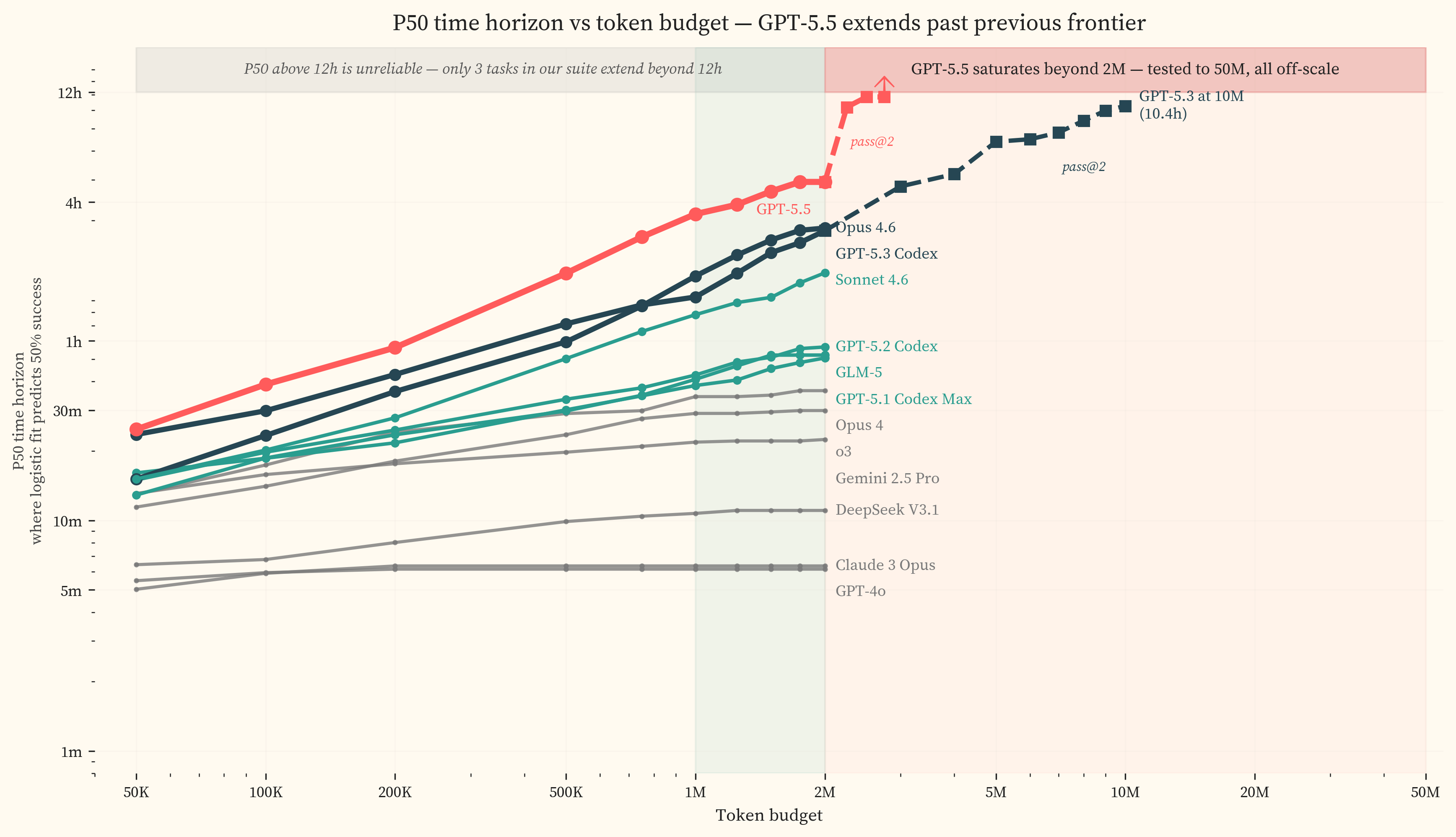
This note adds GPT-5.5 to the dataset and addresses that undercount by extending the token budget to 50M tokens. The combination saturates the dataset. At our 2M budget, GPT-5.5 achieves a P50 of 5.1h. Pushed to 50M tokens it solves 92.4% of tasks and its time horizon pushes off-scale past 12h.
For bounded, verifiable offensive tasks against undefended targets, our dataset cannot resolve GPT-5.5’s time horizon. We speculate that for this task class the time-horizon methodology is no longer fit for purpose.
Background
Since the publication of our original offensive cybersecurity time horizons research note less than two months ago, frontier offensive cyber capabilities have continued to advance at an alarming pace. Anthropic released Claude Mythos Preview [2], a frontier model withheld from general release because of its cybersecurity capabilities, alongside Project Glasswing [3], a programme placing Mythos directly with defenders at organisations running critical infrastructure. OpenAI followed with GPT-5.5 [4], the subject of this note, classified at “High” on the cybersecurity track of its Preparedness Framework [5] (just below Critical) and shipped with new safeguards around scaled agentic vulnerability research and exploit-chaining. The cyber-permissive variant is gated through a Trusted Access for Cyber programme [6].
This note adds GPT-5.5 as one new data point to our previous cyber time horizons study [1]. Its full methodology, dataset, human study, and limitations remain identical to that previous work. In brief, each task carries a human-time difficulty label from professional experts, models are run on each task, a logistic curve is fit per model, and the task duration at which a model crosses 50% success is its time horizon. For GPT-5.5 specifically, we used the same ReAct scaffold from Inspect AI, set reasoning effort to maximum (xhigh), and ran each task once at provider-default temperature, at a 2M-token budget and one-hour wall-clock limit.
That study found a 2024-onward doubling time of 5.7 months. The best early-2026 models, GPT-5.3 Codex and Opus 4.6, reached fiftieth percentile horizons of 3.1h and 3.2h respectively at a 2M-token budget. These fixed 2M-token evaluation budgets materially undercount frontier model capability. To further explore GPT-5.5’s capability on our dataset, we ran a separate token-budget extension to 50M tokens with a 24-hour wall-clock limit. Our own 10M-token re-run on GPT-5.3 Codex in that study had raised its fiftieth percentile horizon from 3.1h to 10.5h [2.4h, 63.5h]. UK AISI and Irregular have since shown cyber task success continuing to climb with no plateau up to 100M tokens [7], and Epoch AI and METR have run MirrorCode at inference budgets up to 1 billion tokens per task with continued capability gains [8].
Results
At a 2M-token budget
GPT-5.5 achieves a P50 of 5.1h [2.9h, 108h], above both prior frontier models (Opus 4.6 at 3.2h, GPT-5.3 Codex at 3.1h). It solves 80.7% (255/316) of tasks with a single attempt.
GPT-5.5 has solved most of our dataset, leaving only a handful of hard tasks at the top of the difficulty range. With one run per task, whether the model succeeds or fails on those few drives the entire upper end of the fit, producing a wide confidence interval (fitted P50 5.1h, upper bound 108.5h). For the same reason we cap reported horizons at 12 hours. Only three tasks in our dataset extend past that threshold, not enough to estimate a success rate.
| Benchmark | Opus 4.6 @ 2M | GPT-5.3 Codex @ 2M | GPT-5.5 @ 2M | GPT-5.5 @ 10M | GPT-5.5 @ 50M |
|---|---|---|---|---|---|
| CyBench | 90.6% | 87.5% | 100% | 100% | 100% |
| InterCode-CTF | 100% | 100% | 100% | 100% | 100% |
| NL2Bash | 88.9% | 100% | 100% | 100% | 100% |
| CyBashBench | 96.2% | 93.6% | 93.6% | 93.6% | 93.6% |
| NYUCTF | 75.8% | 66.7% | 81.8% | 87.9% | 87.9% |
| CVEBench | 73.3% | 66.7% | 80% | 93.3% | 93.3% |
| CyberGym | 43.7% | 51.5% | 54.4% | 80.6% | 86.4% |
| Overall | 75.6% | 76.3% | 80.7% | 89.1% | 92.4% |
50M-token budget scaling
We re-ran all 53 GPT-5.5 failures at a 50M-token budget, mirroring the 10M-token re-run on GPT-5.3 Codex in our previous study. 37 passed, of which 23 used more than 2M tokens (token-budget constrained) and 14 used fewer (stochastic variation from single-run evaluation, effectively a pass@2 result). The same split applied to that earlier 5.3 Codex re-run (25 budget, 22 stochastic of 47/83). Overall success rises from 80.7% at 2M to 92.4% after the 50M overlay. Accuracy on CyberGym [9], the hardest benchmark in the suite, jumps 32pp at 50M ().
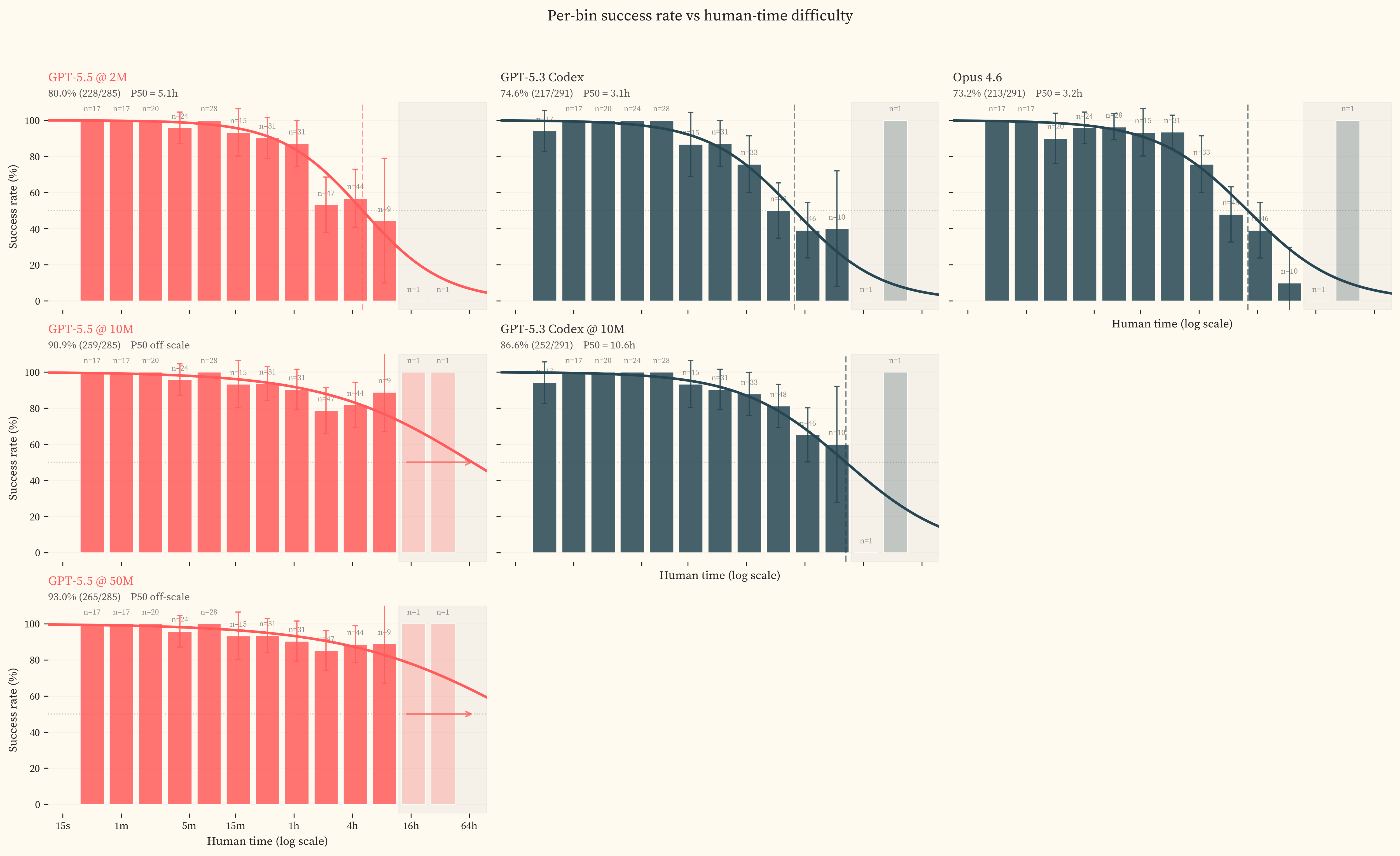
At 50M tokens, GPT-5.5 succeeds on nearly all tasks across the dataset’s full difficulty range. The IRT logistic fit has no transition to anchor to, and the fitted P50 pushes off-scale above 12h. Our dataset cannot measure GPT-5.5’s capability on this task class. Future progress on bounded undefended-target tasks will need harder or differently-shaped tasks.
Discussion
Capability has outpaced measurement against undefended targets
This dataset cannot measure GPT-5.5’s offensive cyber time horizon. Time-horizon methodology requires tasks above the model’s success threshold to anchor the fitted curve, and our dataset no longer contains them. This stems from at least two distinct dataset limits. First, our task class is narrow. Tasks are bounded, verifiable, and undefended, and most are single-target with well-specified objectives. Second, our difficulty range doesn’t extend high enough, with most tasks under 8h of human time. Whether this methodology survives to broader task classes or longer-horizon tasks within offensive cybersecurity remains open.
METR observed the same effect when reporting an evaluation of Claude Mythos Early Preview. The fitted 50% horizon was at least 16 hours (95% CI 8.5h to 55h). METR withheld point estimates above 16h and advised caution on recent time-horizon numbers [10]. Frontier capability has run past the upper end of the difficulty range existing suites can resolve.
Capability is now triggering defensive response, with an open-weight lag close behind
The gap between frontier offensive capability and real-world defender capacity has become a deployment-policy decision for leading labs. Both Mythos and the cyber-permissive variant of GPT-5.5 are at or above the capability level our benchmarks no longer resolve, and both have been gated rather than released openly.
At historical adaptation buffersAdaptation bufferThe time window between when a capability first appears at the closed-source frontier and when it becomes widely accessible through open-weight models [11]. Our March study measured an offensive-cyber-specific buffer of 5.7-13.1 months (GLM-5 and DeepSeek V3.1 projected onto the closed-source trendline)., this capability level can be expected to appear in open-weight form within months. Our previous study measured GLM-5 trailing the closed-source 2024+ trendline by roughly 5.7 months in early 2026 [1]. Assuming those timelines hold, the compressed gap places significant pressure on organisations running critical infrastructure to scale defences before equivalent offensive capability becomes openly available. AI-orchestrated cyber operations at scale have already been observed by frontier AI labs [12]. Assuming the adaptation buffer holds, internet-accessible systems should expect to face equivalent pressure from attackers built on open-weight models within similar timeframes.
In December 2025 we picked the hardest offensive cybersecurity benchmarks we could find for our dataset. By March 2026 that dataset appeared to already be showing signs of saturation. By May 2026 we have shown unequivocally that it is saturated. And timely and conscientious evaluation of frontier model capability appears to be on trend to only get more difficult.
References
- [1]J. Payne, J. Miller, and S. Peters, “Offensive Cybersecurity Time Horizons,” Lyptus Research, Research Note, Apr. 2026. [Online]. Available at: https://lyptusresearch.org/research/offensive-cyber-time-horizons. ↗
- [2]Anthropic, “Claude Mythos Preview System Card.” Apr. 2026, [Online]. Available at: https://red.anthropic.com/2026/mythos-preview/. ↗
- [3]Anthropic, “Project Glasswing: Securing Critical Software for the AI Era.” Apr. 2026, [Online]. Available at: https://www.anthropic.com/glasswing. ↗
- [4]OpenAI, “Introducing GPT-5.5.” Apr. 2026, [Online]. Available at: https://openai.com/index/introducing-gpt-5-5/. ↗
- [5]OpenAI, “Preparedness Framework Version 2.” Apr. 2025, [Online]. Available at: https://cdn.openai.com/pdf/18a02b5d-6b67-4cec-ab64-68cdfbddebcd/preparedness-framework-v2.pdf. ↗
- [6]OpenAI, “GPT-5.5 System Card.” Apr. 2026, [Online]. Available at: https://deploymentsafety.openai.com/gpt-5-5. ↗
- [7]UK AI Safety Institute and Irregular, “Evidence for Inference Scaling in AI Cyber Tasks.” Mar. 2026, [Online]. Available at: https://www.aisi.gov.uk/blog/evidence-for-inference-scaling-in-ai-cyber-tasks-increased-evaluation-budgets-reveal-higher-success-rates. ↗
- [8]Epoch AI and METR, “MirrorCode: Preliminary Results.” Apr. 2026, [Online]. Available at: https://epoch.ai/blog/mirrorcode-preliminary-results. ↗
- [9]Z. Wang, T. Shi, J. He, M. Cai, J. Zhang, and D. Song, “CyberGym: Evaluating AI Agents’ Real-World Cybersecurity Capabilities at Scale.” 2025, [Online]. Available at: https://arxiv.org/abs/2506.02548. ↗
- [10]METR, “Time-horizon evaluation of Claude Mythos Preview (early).” May 2026, [Online]. Available at: https://x.com/METR_Evals/status/2052896621760004602. ↗
- [11]H. Toner, “Nonproliferation is the wrong approach to AI misuse.” Apr. 2025, [Online]. Available at: https://helentoner.substack.com/p/nonproliferation-is-the-wrong-approach. ↗
- [12]Anthropic, “Disrupting the First Reported AI-Orchestrated Cyber Espionage Campaign.” Nov. 2025, [Online]. Available at: https://www.anthropic.com/news/disrupting-AI-espionage. ↗